StreamSets是最近兴起的ETL平台,它的特点是具有多样性的组件支持,可集成于CDH平台。最为吸引人的就是可视化的数据流通流程设置,多个pipelines的编写,RestApi形式的自动化支持,等等等等,当然选择使用它的最终理由还是因为支持的组件多。这一篇就简单来讲讲StreamSets的简单使用。
StreamSets的部署有很多形式,这里列举两个最方便的。
这里我提供一份写好的docker-compose文件,如下
version: '3.1'
services:
streamsets:
image: streamsets/datacollector
restart: always
ports:
- "18630:18630"
environment:
HOST_IP: 0.0.0.0
volumes:
- streamsets:/opt/steramsets
- /data/mdt/data_hbase:/data/hbase
volumes:
streamsets:
这里把端口映射到了18630方便等下的登录使用,HOST_IP改成万能IP,不设置访问限制方便访问,相关数据挂到本地磁盘。
启动命令
sudo docker-compose up -d
直接复制yaml配置创建docker-compose.yaml就可以了
因为StreamSets内部的data collector重启机制问题,会导致组件无法成功添加的问题,所以这里还没有解决,暂不推荐K8S,不过还是把配置文件给出来(组件无法附加版本)
apiVersion: apps/v1
kind: Deployment
metadata:
name: streamsets-datacollector
namespace: default
labels:
app: streamsets-datacollector
spec:
replicas: 1
selector:
matchLabels:
app: streamsets-datacollector
template:
metadata:
labels:
app: streamsets-datacollector
spec:
containers:
- name: streamsets
image: streamsets/datacollector
env:
- name: HOST_IP
value: 0.0.0.0
resources:
limits:
cpu: '1'
memory: 2Gi
requests:
cpu: '1'
memory: 2Gi
volumeMounts: #容器内挂载点
- mountPath: /opt/steramsets
name: stp
- mountPath: /data/hbase
name: sthb
volumes:
- name: stp
hostPath:
path: streamsets
- name: sthb
hostPath:
path: /data/mdt/data_hbase
---
apiVersion: v1
kind: Service
metadata:
labels:
app: streamsets-datacollector
name: streamsets-datacollector
namespace: default
spec:
type: NodePort
ports:
- port: 18630
protocol: TCP
targetPort: 18630
nodePort: 31630
selector:
app: streamsets-datacollector
也是把端口暴露在外部18630
复制下来创建StreamSets.yaml
启动命令
kubectl apply -f StreamSets.yaml -n data-service
这里是使用data-service命名空间,K8S的概念这里不多说了
这个安装方式我就不多说了吧,因为直接在cloudera-manager里面添加角色就行了,具体在那个机器上的角色看自己的需求了。
这里我们简单的举一个HTTP-client数据获取的例子。
为了方便起见,我们先创建一个test.txt文件,内容可以如下:
name,age
symoon,18
willson,50
这里用,分割,方便那我们取数据。
当然也可以自己设置测试数据,这里随便写了一个。
接下来我们简单开启一个python服务,用来启动一个api
python3 -m http.server 8001
这个不多说了,大家应该都知道,这条命令在txt所在文件夹启动,这时候访问
http://127.0.0.1:8001/test.txt
这个API就是我们需要的数据。接下来我们到StreamSets里面操作。

账号密码都是默认的admin
输入正确后,我们进入到主页面
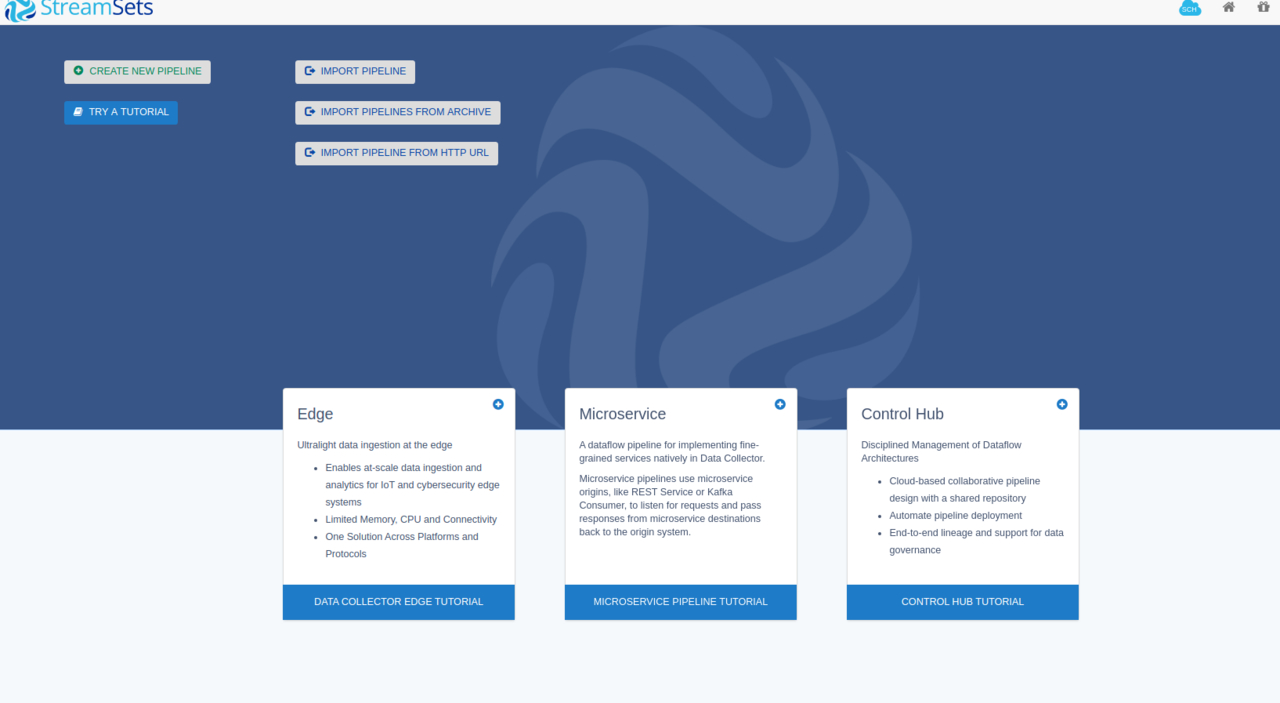
点击CREATE NEW PIPELINE创建一个新的任务,Title什么的随便填,我直接填了test
创建成功后我们进入到任务管理界面:
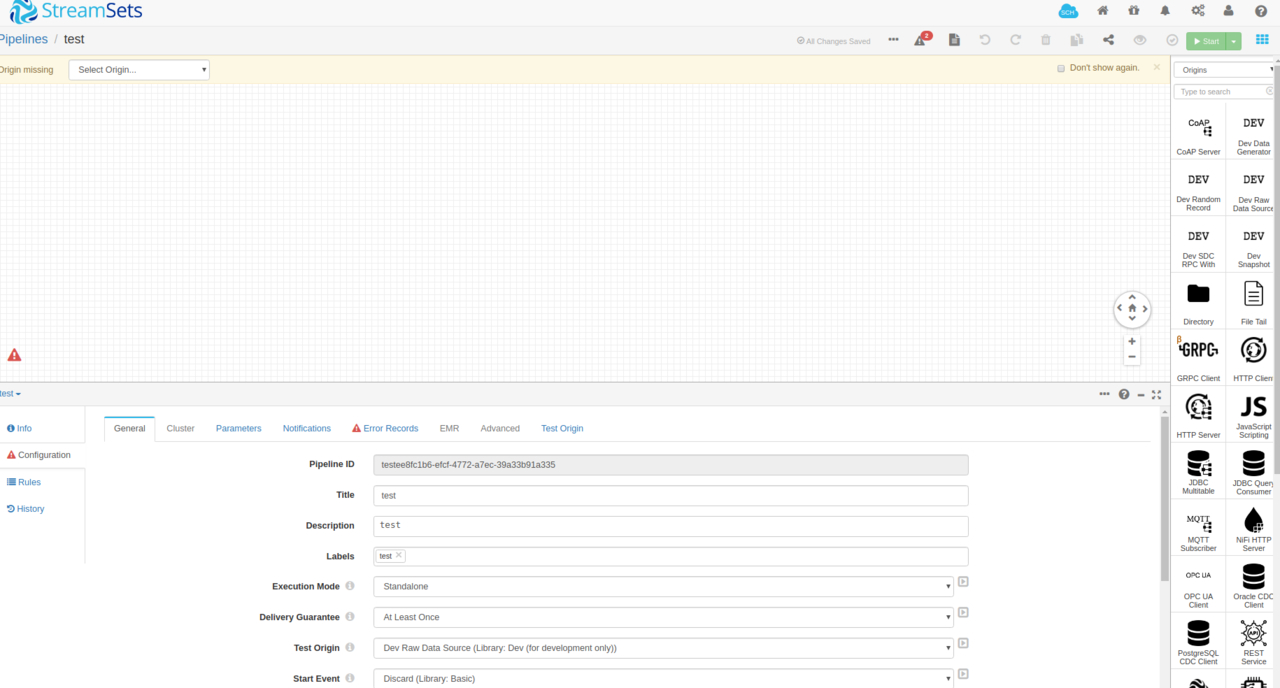
我们选择拖拽一个HTTP Client作为数据源。相关配置如下填写,这里我们用docker启动的StreamSets的化就无法用127.0.0.1了,我们使用本机的IP
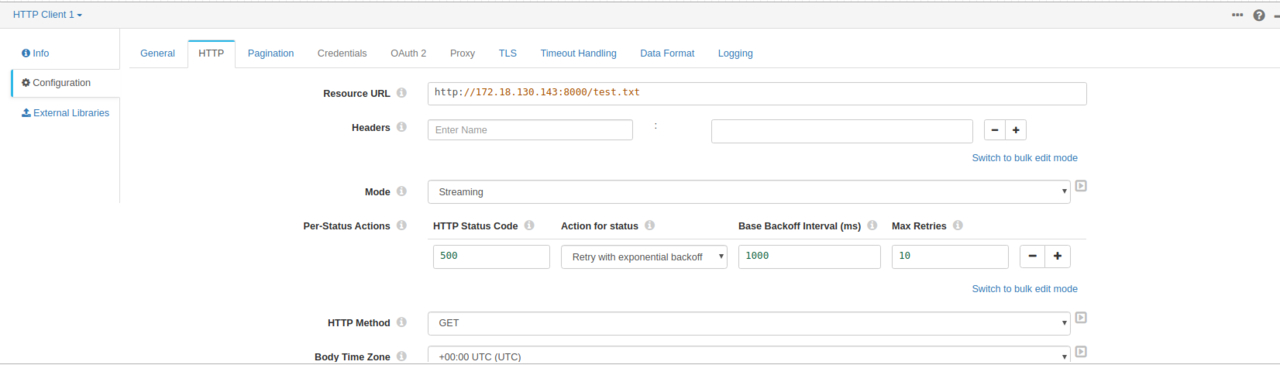

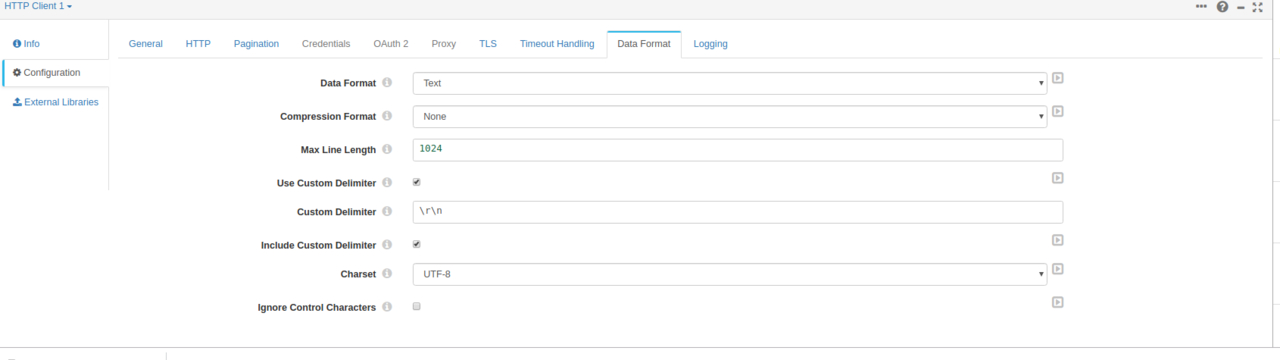
这里填写的信息都有说明,相信大家都能看懂就不多说了,接下来测试一下,我们点击一下右上角类似眼睛的按钮。
默认信息就好,批量可以从10改成1。结果如图
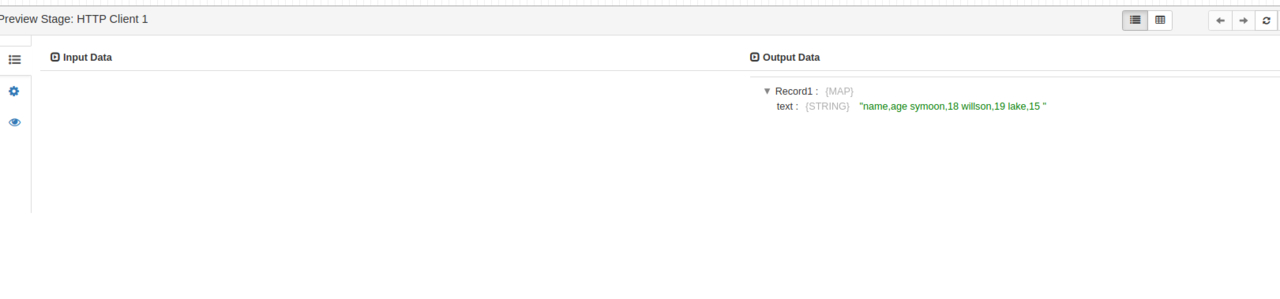
这里我们举个简单的增量采集案例,采集Mysql指定表中的增量数据到Kafka中。
接下来来实战一下,我们先创建一个pipeline,上面已经说明了,就不多说了。
因为mysql的connector需要安装jdbc组件,所以我们需要进行组件安装。进入Pipeline中的界面,以如下方式选择。

点击加号 Add/Remove Stages,进入到组件安装界面。

这里我们找到JDBC,点击右侧的配置按钮,点击install。
因为我们需要用到Kafka服务,这里我们继续进入Apache Kafka中,安装Kafka-V2.0版本。安装成功后会提示重启,根据提示点击Restart data collector按钮即可。等待一分钟左右服务重启即可。
重新进入到我们刚才创建的Pipeline,配置JDBC拖动的组件及配置如下:
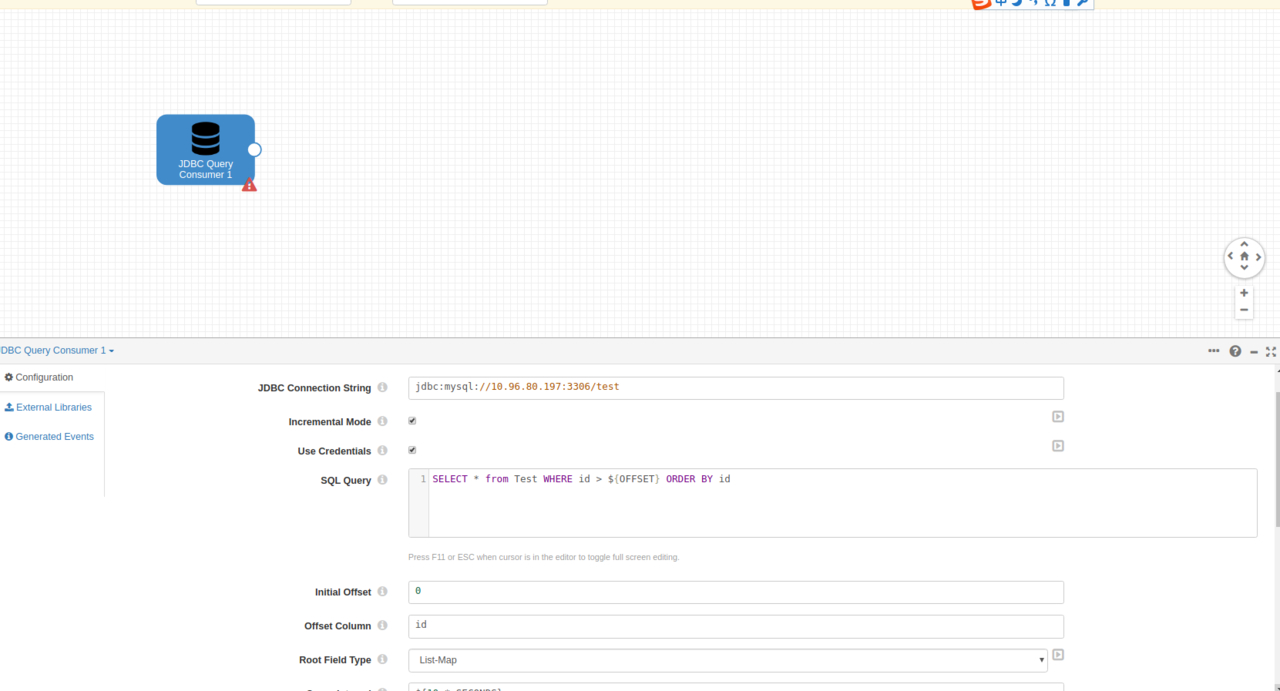
这里我们的数据库名字和表名字分别是test和Test,偏移值由id字段来计算。初始值设置0。
因为jdbc需要相应的驱动,所以我们需要在External Libraries处上传mysql的jdbc驱动。这里直接附上一份。
mysqlconnectorjava8.0.18.jar
下载好后上传,依旧需要重启服务生效。
后面还需要提供账号密码,这里就不截图多说了。
这时候依旧是点那个眼睛按钮测试一下,首先我们还是需要在数据库里面创建这张表的,具体格式如下
id|name|age
1|symoon|18
2|willson|19
3|lake|20
大概这种表格式,测试后结果如下:

这时候我们已经拿到了增量数据,接下来配置Kafka的数据接收端。
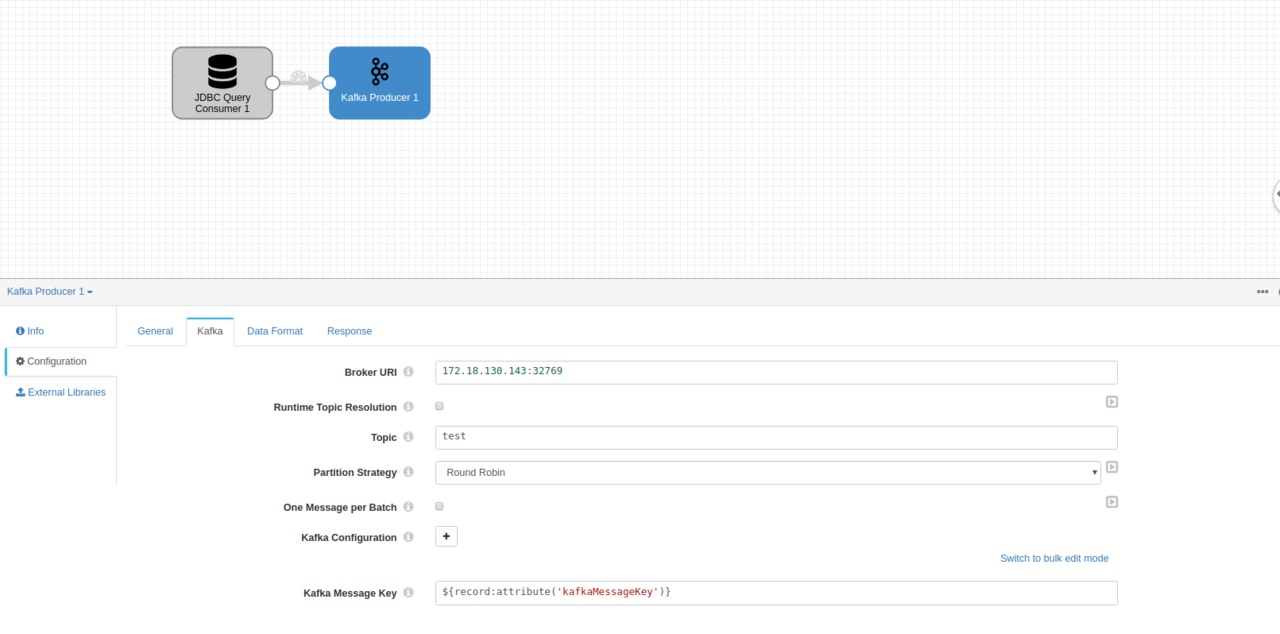
这里我们在上面的接收端选择直接选择Kafka producer就可以了,我使用的是本机docker启动的Kafka具体的配置我就不发了,在之前的一键启动docker程序里面有,topic随便输入一个test,接下来还是点击眼睛测试一下。

kafka的input成功了,接下来我们直接运行起来。
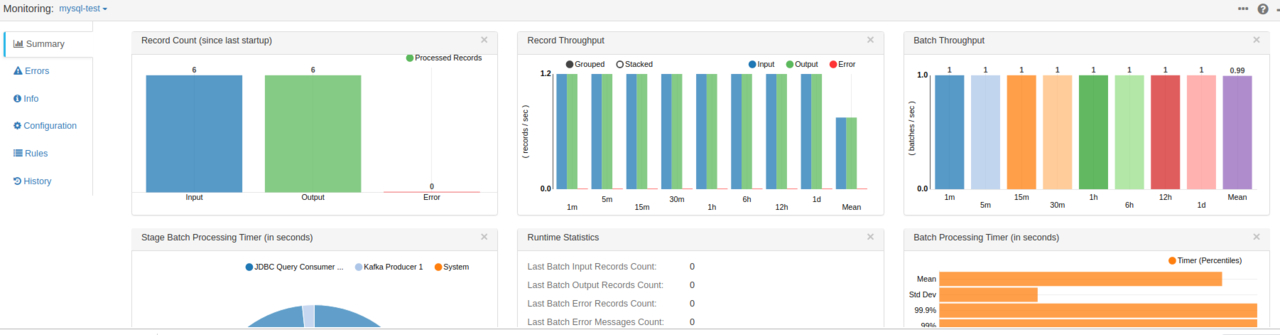
数据流通的性能还有一些相关信息都在这里显示了,这个任务会一直运行着,增量数据都可以流通到Kafka,其他的数据库使用其他连接器也可以支持,这里就不多说了,大家可以都一一去试试。
 symoon笔记
symoon笔记